A couple of days ago, the following flow chart by Alekandr Tiulkanov crossed my desk:
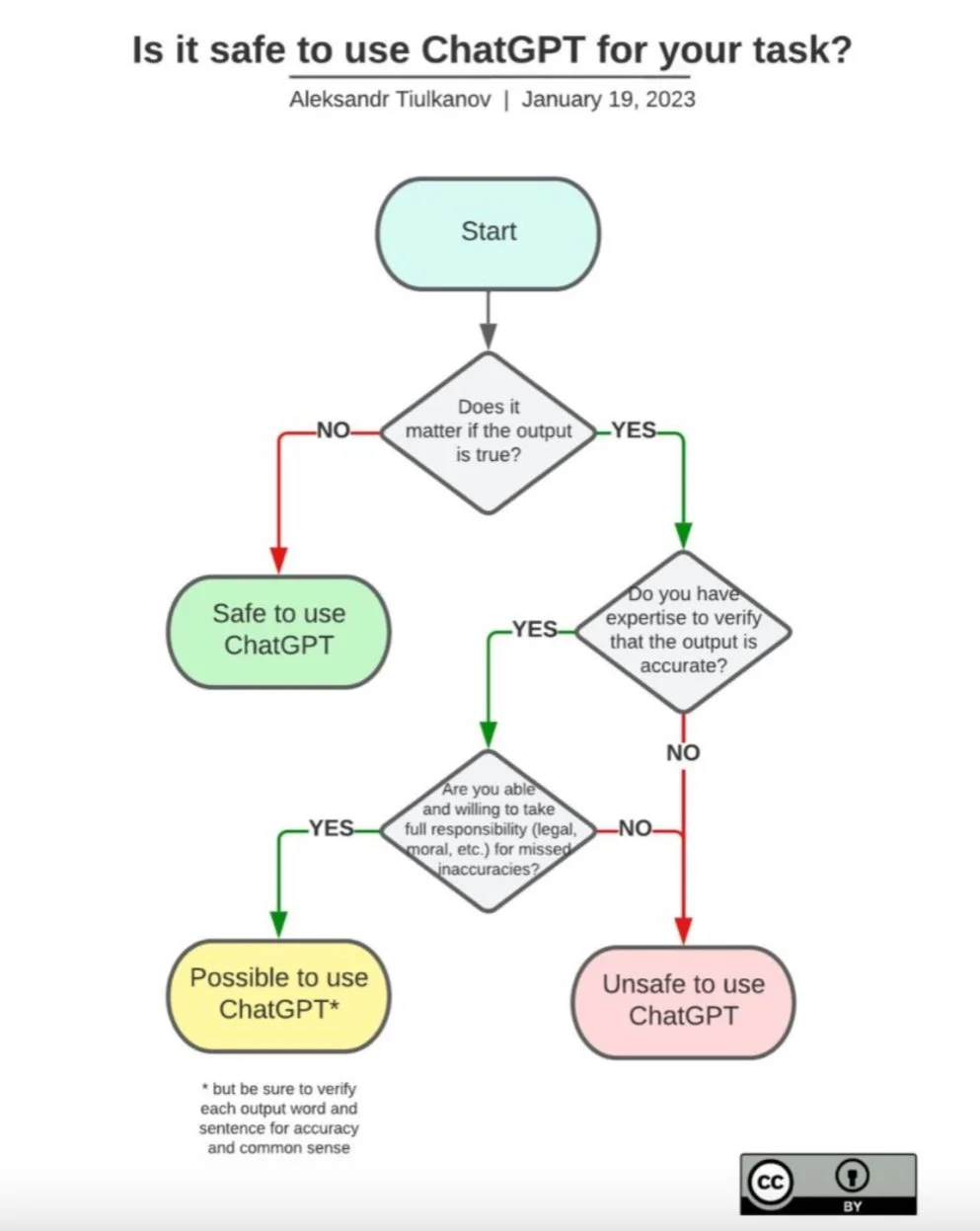
After some staring and thinking, i came to the conclusion that this was overly simplified to the extent that it was dangerous, considering all the things I have read and discussed with people about chatGPT in the last couple of days.
There are several issues I have with the original diagram:
»Safe« is a word that carries a lot of ambiguity. Seeing that OpenAI is, despite the name, not an open initiative of any kind at all, but a commercial entity with the purpose to earn money, we have to assume that they use the data they collect to, among other things, monetize it: »Their terms are quite clear about collecting and using data themselves as well as sharing/selling to third parties« (Autumn Caines). Given that among the founders of OpenAI are such people as »privacy is for old people« Reid Hoffman, Palantir-Cofounder Peter Thiel and »no further quotes needed« Elon Musk, I have exactly zero trust that anything typed into chatGPT is not only agressively monetized, but also fed into detailled profiles they hold about their users. At this point, it is a good idea to know about ELIZA, and how one of Weizenbaums cathartic observations was that people asked him to leave the room because they wanted to discuss private matters with this first chatbot in 1965. My conclusion is that people will inevitably reveal a lot of private information to a company that never ever had »don’t be evil« as their motto. ChatGPT has even been described as a data privacy nightmare. Bottom line: chatGPT is never safe.
Of course, a more benevolent interpretation of »safe« in this context is to understand it in regard of the result, as in: Can we rely on the factual correctness of the result? A question that leads us into a completely different territory; the first questions down the diagram implies that every output of chatGPT is either true or not true – which is a terribly flawed assumption. For some statements, this is obviously acceptable: when someone states the height of the eiffel tower, they can be right or wrong, in which case their statement is true or false, respectively. But not far from that, we find the now infamous »song in the style of Nick Cave«, which provoked quite an outspoken response by the real Nick Cave (TL;DR: he didn’t like it. at all.). This chatGPT output obviously cannot be categorized into »true« or »false«: it is neither right nor wrong, it is (probably) just bad, and it is breaking the flow chart in the first question. But, is it safe to use ChatGPT for such a case?
»Are you able to and willing to take full responsibility?« is the next question that stands out. Is that even possible? I imagine it comes down to considering the consequences of publishing the text as if it was written by me, and being ready to accept the repercussions of this. Maybe this question implies that we should not hide behind »Oh, an AI wrote this«. Here, I fully agree, and even giving my grave resentment of the scientific publishing circus (which will become another blog post, for sure) I second the initiatives to ban AI co-authorship: text generated using technology should be treated as if the person using technology to generate the text has written this text. This is self-evident for spell-checking and autocomplete as well as for systems that help us create consistent references, and it applies here as well. (this last italic part was added after publishing to clarify what I mean)
The diagram happily igores all questions beyond the output of chatGPT, and pretends we can treat the output of large LLMs as »just another piece of text«. I’ve discussed a couple of the problems coming from this frame, and want to add one more: is it safe to use for the hidden fleet of human workers that sanitized the training data, who risked their mental health for very little money?
So, after much consideration, I would like to propose a slightly modified version of the diagram: